
這(zhè)才是kafka
文(wén)章轉載自(zì):https://www.jianshu.com/p/d3e963ff8b70
作(zuò)者:鄭傑文(wén),騰訊雲存儲,高(gāo)級後台工(gōng)程師
簡介
kafka是一個分布式消息隊列。具有高(gāo)性能(néng)、持久化、多副本備份、橫向擴展能(néng)力。生産者往隊列裏寫消息,消費者從(cóng)隊列裏取消息進行業務邏輯。一般在架構設計(jì)中起到(dào)解耦、削峰、異步處理(lǐ)的作(zuò)用(yòng)。
kafka對(duì)外(wài)使用(yòng)topic的概念,生産者往topic裏寫消息,消費者從(cóng)讀消息。爲了(le)做到(dào)水(shuǐ)平擴展,一個topic實際是由多個partition組成的,遇到(dào)瓶頸時(shí),可以通過增加partition的數量來(lái)進行橫向擴容。單個parition内是保證消息有序。每新寫一條消息,kafka就是在對(duì)應的文(wén)件append寫,所以性能(néng)非常高(gāo)。kafka的總體數據流是這(zhè)樣的:
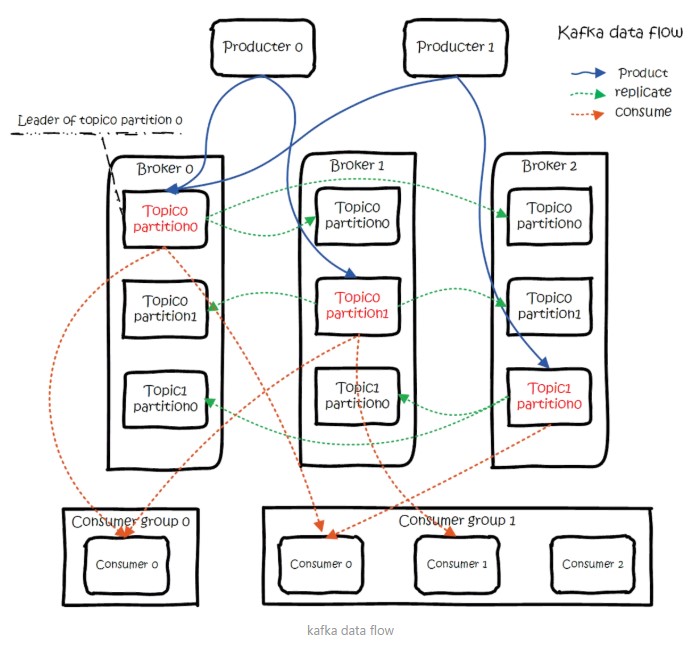
大(dà)概用(yòng)法就是,Producers往Brokers裏面的指定Topic中寫消息,Consumers從(cóng)Brokers裏面拉去指定Topic的消息,然後進行業務處理(lǐ)。
圖中有兩個topic,topic 0有兩個partition,topic 1有一個partition,三副本備份。可以看(kàn)到(dào)consumer gourp 1中的consumer 2沒有分到(dào)partition處理(lǐ),這(zhè)是有可能(néng)出現(xiàn)的,下(xià)面會(huì)講到(dào)。關于broker、topics、partitions的一些(xiē)元信息用(yòng)zk來(lái)存,監控和(hé)路由啥的也(yě)都會(huì)用(yòng)到(dào)zk。
生産
基本流程是這(zhè)樣的
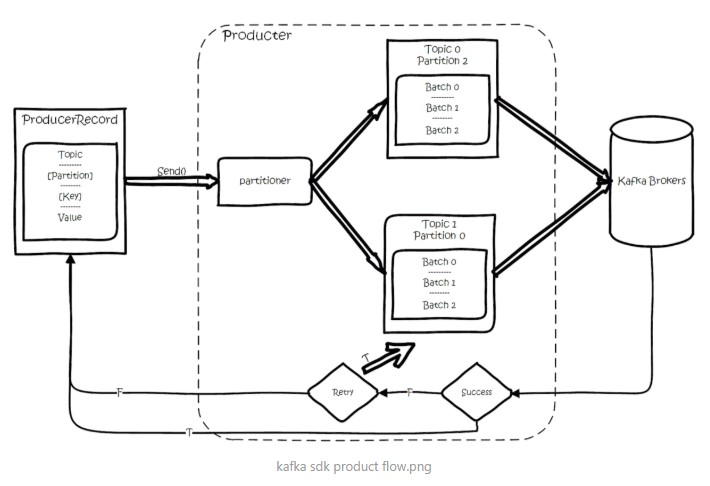
創建一條記錄,記錄中一個要指定對(duì)應的topic和(hé)value,key和(hé)partition可選。
先序列化,然後按照topic和(hé)partition,放(fàng)進對(duì)應的發送隊列中。kafka produce都是批量請(qǐng)求,會(huì)積攢一批,然後一起發送,不是調send()就進行立刻進行網絡發包。
如果partition沒填,那麽情況會(huì)是這(zhè)樣的:
1、key有填
按照key進行哈希,相同key去一個partition。(如果擴展了(le)partition的數量那麽就不能(néng)保證了(le))
2、key沒填
round-robin來(lái)選partition
這(zhè)些(xiē)要發往同一個partition的請(qǐng)求按照配置,攢一波,然後由一個單獨的線程一次性發過去。
API
有high level api,替我們把很(hěn)多事(shì)情都幹了(le),offset,路由啥都替我們幹了(le),用(yòng)以來(lái)很(hěn)簡單。
還有simple api,offset啥的都是要我們自(zì)己記錄。
partition
當存在多副本的情況下(xià),會(huì)盡量把多個副本,分配到(dào)不同的broker上(shàng)。kafka會(huì)爲partition選出一個leader,之後所有該partition的請(qǐng)求,實際操作(zuò)的都是leader,然後再同步到(dào)其他(tā)的follower。當一個broker歇菜後,所有leader在該broker上(shàng)的partition都會(huì)重新選舉,選出一個leader。(這(zhè)裏不像分布式文(wén)件存儲系統那樣會(huì)自(zì)動進行複制保持副本數)
然後這(zhè)裏就涉及兩個細節:怎麽分配partition,怎麽選leader。
關于partition的分配,還有leader的選舉,總得有個執行者。在kafka中,這(zhè)個執行者就叫controller。kafka使用(yòng)zk在broker中選出一個controller,用(yòng)于partition分配和(hé)leader選舉。
partition的分配
1、将所有Broker(假設共n個Broker)和(hé)待分配的Partition排序
2、将第i個Partition分配到(dào)第(i mod n)個Broker上(shàng) (這(zhè)個就是leader)
3、将第i個Partition的第j個Replica分配到(dào)第((i + j) mode n)個Broker上(shàng)
leader容災
controller會(huì)在Zookeeper的/brokers/ids節點上(shàng)注冊Watch,一旦有broker宕機,它就能(néng)知(zhī)道(dào)。當broker宕機後,controller就會(huì)給受到(dào)影響的partition選出新leader。controller從(cóng)zk的/brokers/topics/[topic]/partitions/[partition]/state中,讀取對(duì)應partition的ISR(in-sync replica已同步的副本)列表,選一個出來(lái)做leader。
選出leader後,更新zk,然後發送LeaderAndISRRequest給受影響的broker,讓它們改變知(zhī)道(dào)這(zhè)事(shì)。爲什(shén)麽這(zhè)裏不是使用(yòng)zk通知(zhī),而是直接給broker發送rpc請(qǐng)求,我的理(lǐ)解可能(néng)是這(zhè)樣做zk有性能(néng)問題吧。
如果ISR列表是空(kōng),那麽會(huì)根據配置,随便選一個replica做leader,或者幹脆這(zhè)個partition就是歇菜。如果ISR列表的有機器,但(dàn)是也(yě)歇菜了(le),那麽還可以等ISR的機器活過來(lái)。
多副本同步
這(zhè)裏的策略,服務端這(zhè)邊的處理(lǐ)是follower從(cóng)leader批量拉取數據來(lái)同步。但(dàn)是具體的可靠性,是由生産者來(lái)決定的。
生産者生産消息的時(shí)候,通過request.required.acks參數來(lái)設置數據的可靠性。

在acks=-1的時(shí)候,如果ISR少于min.insync.replicas指定的數目,那麽就會(huì)返回不可用(yòng)。
這(zhè)裏ISR列表中的機器是會(huì)變化的,根據配置replica.lag.time.max.ms,多久沒同步,就會(huì)從(cóng)ISR列表中剔除。以前還有根據落後多少條消息就踢出ISR,在1.0版本後就去掉了(le),因爲這(zhè)個值很(hěn)難取,在高(gāo)峰的時(shí)候很(hěn)容易出現(xiàn)節點不斷的進出ISR列表。
從(cóng)ISA中選出leader後,follower會(huì)從(cóng)把自(zì)己日志中上(shàng)一個高(gāo)水(shuǐ)位後面的記錄去掉,然後去和(hé)leader拿新的數據。因爲新的leader選出來(lái)後,follower上(shàng)面的數據,可能(néng)比新leader多,所以要截取。這(zhè)裏高(gāo)水(shuǐ)位的意思,對(duì)于partition和(hé)leader,就是所有ISR中都有的最新一條記錄。消費者最多隻能(néng)讀到(dào)高(gāo)水(shuǐ)位;
從(cóng)leader的角度來(lái)說高(gāo)水(shuǐ)位的更新會(huì)延遲一輪,例如寫入了(le)一條新消息,ISR中的broker都fetch到(dào)了(le),但(dàn)是ISR中的broker隻有在下(xià)一輪的fetch中才能(néng)告訴leader。
也(yě)正是由于這(zhè)個高(gāo)水(shuǐ)位延遲一輪,在一些(xiē)情況下(xià),kafka會(huì)出現(xiàn)丢數據和(hé)主備數據不一緻的情況,0.11開(kāi)始,使用(yòng)leader epoch來(lái)代替高(gāo)水(shuǐ)位。(https://cwiki.apache.org/confluence/display/KAFKA/KIP-101+-+Alter+Replication+Protocol+to+use+Leader+Epoch+rather+than+High+Watermark+for+Truncation#KIP-101-AlterReplicationProtocoltouseLeaderEpochratherthanHighWatermarkforTruncation-Scenario1:HighWatermarkTruncationfollowedbyImmediateLeaderElection)
思考:
當acks=-1時(shí)
1、是follwers都來(lái)fetch就返回成功,還是等follwers第二輪fetch?
2、leader已經寫入本地,但(dàn)是ISR中有些(xiē)機器失敗,那麽怎麽處理(lǐ)呢(ne)?
消費
訂閱topic是以一個消費組來(lái)訂閱的,一個消費組裏面可以有多個消費者。同一個消費組中的兩個消費者,不會(huì)同時(shí)消費一個partition。換句話(huà)來(lái)說,就是一個partition,隻能(néng)被消費組裏的一個消費者消費,但(dàn)是可以同時(shí)被多個消費組消費。因此,如果消費組内的消費者如果比partition多的話(huà),那麽就會(huì)有個别消費者一直空(kōng)閑。
API
訂閱topic時(shí),可以用(yòng)正則表達式,如果有新topic匹配上(shàng),那能(néng)自(zì)動訂閱上(shàng)。
offset的保存
一個消費組消費partition,需要保存offset記錄消費到(dào)哪,以前保存在zk中,由于zk的寫性能(néng)不好(hǎo),以前的解決方法都是consumer每隔一分鐘(zhōng)上(shàng)報(bào)一次。這(zhè)裏zk的性能(néng)嚴重影響了(le)消費的速度,而且很(hěn)容易出現(xiàn)重複消費。
在0.10版本後,kafka把這(zhè)個offset的保存,從(cóng)zk總剝離,保存在一個名叫__consumeroffsets topic的topic中。寫進消息的key由groupid、topic、partition組成,value是偏移量offset。topic配置的清理(lǐ)策略是compact。總是保留最新的key,其餘删掉。一般情況下(xià),每個key的offset都是緩存在内存中,查詢的時(shí)候不用(yòng)遍曆partition,如果沒有緩存,第一次就會(huì)遍曆partition建立緩存,然後查詢返回。
确定consumer group位移信息寫入__consumers_offsets的哪個partition,具體計(jì)算(suàn)公式:
__consumers_offsets partition =
Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)
//groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,默認是50個分區(qū)。
思考:
如果正在跑的服務,修改了(le)offsets.topic.num.partitions,那麽offset的保存是不是就亂套了(le)?
分配partition--reblance
生産過程中broker要分配partition,消費過程這(zhè)裏,也(yě)要分配partition給消費者。類似broker中選了(le)一個controller出來(lái),消費也(yě)要從(cóng)broker中選一個coordinator,用(yòng)于分配partition。
下(xià)面從(cóng)頂向下(xià),分别闡述一下(xià)
1、怎麽選coordinator。
2、交互流程。
3、reblance的流程。
選coordinator
1、看(kàn)offset保存在那個partition
2、該partition leader所在的broker就是被選定的coordinator
這(zhè)裏我們可以看(kàn)到(dào),consumer group的coordinator,和(hé)保存consumer group offset的partition leader是同一台機器。
交互流程
把coordinator選出來(lái)之後,就是要分配了(le)
整個流程是這(zhè)樣的:
1、consumer啓動、或者coordinator宕機了(le),consumer會(huì)任意請(qǐng)求一個broker,發送ConsumerMetadataRequest請(qǐng)求,broker會(huì)按照上(shàng)面說的方法,選出這(zhè)個consumer對(duì)應coordinator的地址。
2、consumer 發送heartbeat請(qǐng)求給coordinator,返回IllegalGeneration的話(huà),就說明(míng)consumer的信息是舊的了(le),需要重新加入進來(lái),進行reblance。返回成功,那麽consumer就從(cóng)上(shàng)次分配的partition中繼續執行。
reblance流程
1、consumer給coordinator發送JoinGroupRequest請(qǐng)求。
2、這(zhè)時(shí)其他(tā)consumer發heartbeat請(qǐng)求過來(lái)時(shí),coordinator會(huì)告訴他(tā)們,要reblance了(le)。
3、其他(tā)consumer發送JoinGroupRequest請(qǐng)求。
4、所有記錄在冊的consumer都發了(le)JoinGroupRequest請(qǐng)求之後,coordinator就會(huì)在這(zhè)裏consumer中随便選一個leader。然後回JoinGroupRespone,這(zhè)會(huì)告訴consumer你(nǐ)是follower還是leader,對(duì)于leader,還會(huì)把follower的信息帶給它,讓它根據這(zhè)些(xiē)信息去分配partition
5、consumer向coordinator發送SyncGroupRequest,其中leader的SyncGroupRequest會(huì)包含分配的情況。
6、coordinator回包,把分配的情況告訴consumer,包括leader。
當partition或者消費者的數量發生變化時(shí),都得進行reblance。
列舉一下(xià)會(huì)reblance的情況:
1、增加partition
<p style="margin-top: 0px;margin-bottom: 0.8rem;padding: 0px;list-style: none;-webkit-font-smoothing: antialiased