
本文(wén)經授權轉載自(zì)SegmentFault思否(作(zuò)者:huashiou)
1、概述
本文(wén)以淘寶作(zuò)爲例子,介紹從(cóng)一百個并發到(dào)千萬級并發情況下(xià)服務端的架構的演進過程,同時(shí)列舉出每個演進階段會(huì)遇到(dào)的相關技術,讓大(dà)家對(duì)架構的演進有一個整體的認知(zhī),文(wén)章最後彙總了(le)一些(xiē)架構設計(jì)的原則。
2、基本概念
在介紹架構之前,爲了(le)避免部分讀者對(duì)架構設計(jì)中的一些(xiē)概念不了(le)解,下(xià)面對(duì)幾個最基礎的概念進行介紹:
分布式系統中的多個模塊在不同服務器上(shàng)部署,即可稱爲分布式系統,如Tomcat和(hé)數據庫分别部署在不同的服務器上(shàng),或兩個相同功能(néng)的Tomcat分别部署在不同服務器上(shàng)
高(gāo)可用(yòng)系統中部分節點失效時(shí),其他(tā)節點能(néng)夠接替它繼續提供服務,則可認爲系統具有高(gāo)可用(yòng)性
集群一個特定領域的軟件部署在多台服務器上(shàng)并作(zuò)爲一個整體提供一類服務,這(zhè)個整體稱爲集群。如Zookeeper中的Master和(hé)Slave分别部署在多台服務器上(shàng),共同組成一個整體提供集中配置服務。在常見的集群中,客戶端往往能(néng)夠連接任意一個節點獲得服務,并且當集群中一個節點掉線時(shí),其他(tā)節點往往能(néng)夠自(zì)動的接替它繼續提供服務,這(zhè)時(shí)候說明(míng)集群具有高(gāo)可用(yòng)性
負載均衡請(qǐng)求發送到(dào)系統時(shí),通過某些(xiē)方式把請(qǐng)求均勻分發到(dào)多個節點上(shàng),使系統中每個節點能(néng)夠均勻的處理(lǐ)請(qǐng)求負載,則可認爲系統是負載均衡的
正向代理(lǐ)和(hé)反向代理(lǐ)系統内部要訪問外(wài)部網絡時(shí),統一通過一個代理(lǐ)服務器把請(qǐng)求轉發出去,在外(wài)部網絡看(kàn)來(lái)就是代理(lǐ)服務器發起的訪問,此時(shí)代理(lǐ)服務器實現(xiàn)的是正向代理(lǐ);當外(wài)部請(qǐng)求進入系統時(shí),代理(lǐ)服務器把該請(qǐng)求轉發到(dào)系統中的某台服務器上(shàng),對(duì)外(wài)部請(qǐng)求來(lái)說,與之交互的隻有代理(lǐ)服務器,此時(shí)代理(lǐ)服務器實現(xiàn)的是反向代理(lǐ)。簡單來(lái)說,正向代理(lǐ)是代理(lǐ)服務器代替系統内部來(lái)訪問外(wài)部網絡的過程,反向代理(lǐ)是外(wài)部請(qǐng)求訪問系統時(shí)通過代理(lǐ)服務器轉發到(dào)内部服務器的過程。
3、架構演進
3.1、單機架構
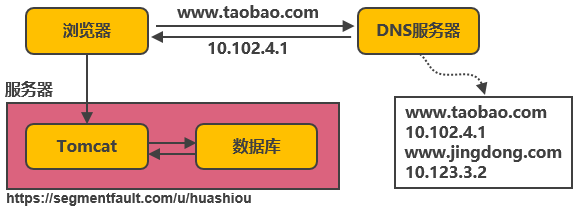
以淘寶作(zuò)爲例子。在網站(zhàn)最初時(shí),應用(yòng)數量與用(yòng)戶數都較少,可以把Tomcat和(hé)數據庫部署在同一台服務器上(shàng)。浏覽器往www.taobao.com發起請(qǐng)求時(shí),首先經過DNS服務器(域名系統)把域名轉換爲實際IP地址10.102.4.1,浏覽器轉而訪問該IP對(duì)應的Tomcat。
随着用(yòng)戶數的增長,Tomcat和(hé)數據庫之間競争資源,單機性能(néng)不足以支撐業務
3.2、第一次演進:Tomcat與數據庫分開(kāi)部署
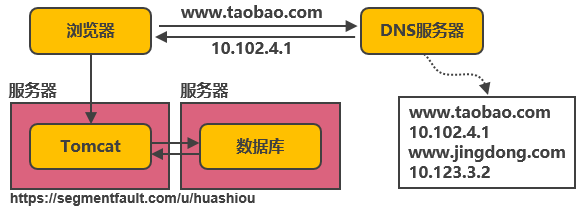
Tomcat和(hé)數據庫分别獨占服務器資源,顯著提高(gāo)兩者各自(zì)性能(néng)。
随着用(yòng)戶數的增長,并發讀寫數據庫成爲瓶頸
3.3、第二次演進:引入本地緩存和(hé)分布式緩存
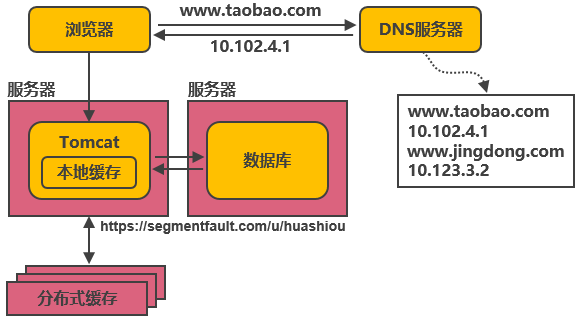
在Tomcat同服務器上(shàng)或同JVM中增加本地緩存,并在外(wài)部增加分布式緩存,緩存熱門(mén)商品信息或熱門(mén)商品的html頁面等。通過緩存能(néng)把絕大(dà)多數請(qǐng)求在讀寫數據庫前攔截掉,大(dà)大(dà)降低(dī)數據庫壓力。其中涉及的技術包括:使用(yòng)memcached作(zuò)爲本地緩存,使用(yòng)Redis作(zuò)爲分布式緩存,還會(huì)涉及緩存一緻性、緩存穿透/擊穿、緩存雪崩、熱點數據集中失效等問題。
緩存抗住了(le)大(dà)部分的訪問請(qǐng)求,随着用(yòng)戶數的增長,并發壓力主要落在單機的Tomcat上(shàng),響應逐漸變慢
3.4、第三次演進:引入反向代理(lǐ)實現(xiàn)負載均衡
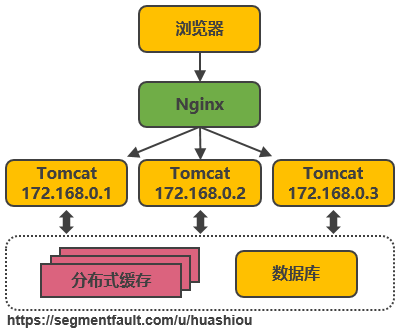
在多台服務器上(shàng)分别部署Tomcat,使用(yòng)反向代理(lǐ)軟件(Nginx)把請(qǐng)求均勻分發到(dào)每個Tomcat中。此處假設Tomcat最多支持100個并發,Nginx最多支持50000個并發,那麽理(lǐ)論上(shàng)Nginx把請(qǐng)求分發到(dào)500個Tomcat上(shàng),就能(néng)抗住50000個并發。其中涉及的技術包括:Nginx、HAProxy,兩者都是工(gōng)作(zuò)在網絡第七層的反向代理(lǐ)軟件,主要支持http協議(yì),還會(huì)涉及session共享、文(wén)件上(shàng)傳下(xià)載的問題。
反向代理(lǐ)使應用(yòng)服務器可支持的并發量大(dà)大(dà)增加,但(dàn)并發量的增長也(yě)意味着更多請(qǐng)求穿透到(dào)數據庫,單機的數據庫最終成爲瓶頸
3.5、第四次演進:數據庫讀寫分離
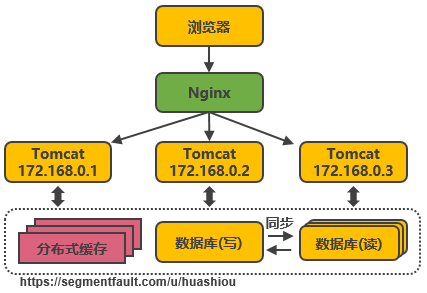
把數據庫劃分爲讀庫和(hé)寫庫,讀庫可以有多個,通過同步機制把寫庫的數據同步到(dào)讀庫,對(duì)于需要查詢最新寫入數據場景,可通過在緩存中多寫一份,通過緩存獲得最新數據。其中涉及的技術包括:Mycat,它是數據庫中間件,可通過它來(lái)組織數據庫的分離讀寫和(hé)分庫分表,客戶端通過它來(lái)訪問下(xià)層數據庫,還會(huì)涉及數據同步,數據一緻性的問題。
業務逐漸變多,不同業務之間的訪問量差距較大(dà),不同業務直接競争數據庫,相互影響性能(néng)
3.6、第五次演進:數據庫按業務分庫
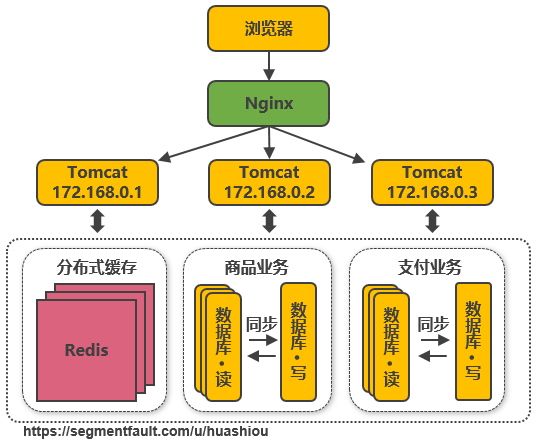
把不同業務的數據保存到(dào)不同的數據庫中,使業務之間的資源競争降低(dī),對(duì)于訪問量大(dà)的業務,可以部署更多的服務器來(lái)支撐。這(zhè)樣同時(shí)導緻跨業務的表無法直接做關聯分析,需要通過其他(tā)途徑來(lái)解決,但(dàn)這(zhè)不是本文(wén)讨論的重點,有興趣的可以自(zì)行搜索解決方案。
随着用(yòng)戶數的增長,單機的寫庫會(huì)逐漸會(huì)達到(dào)性能(néng)瓶頸
3.7、第六次演進:把大(dà)表拆分爲小(xiǎo)表
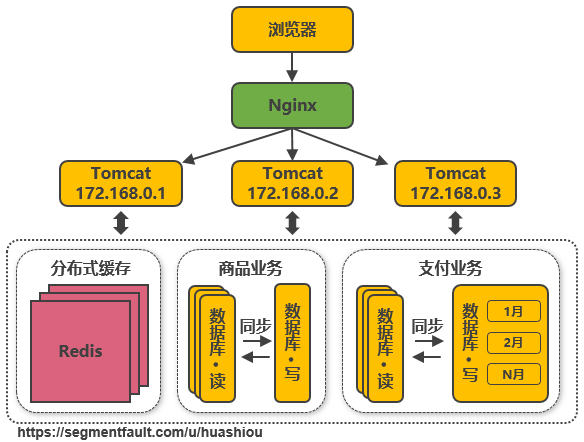
比如針對(duì)評論數據,可按照商品ID進行hash,路由到(dào)對(duì)應的表中存儲;針對(duì)支付記錄,可按照小(xiǎo)時(shí)創建表,每個小(xiǎo)時(shí)表繼續拆分爲小(xiǎo)表,使用(yòng)用(yòng)戶ID或記錄編号來(lái)路由數據。隻要實時(shí)操作(zuò)的表數據量足夠小(xiǎo),請(qǐng)求能(néng)夠足夠均勻的分發到(dào)多台服務器上(shàng)的小(xiǎo)表,那數據庫就能(néng)通過水(shuǐ)平擴展的方式來(lái)提高(gāo)性能(néng)。其中前面提到(dào)的Mycat也(yě)支持在大(dà)表拆分爲小(xiǎo)表情況下(xià)的訪問控制。
這(zhè)種做法顯著的增加了(le)數據庫運維的難度,對(duì)DBA的要求較高(gāo)。數據庫設計(jì)到(dào)這(zhè)種結構時(shí),已經可以稱爲分布式數據庫,但(dàn)是這(zhè)隻是一個邏輯的數據庫整體,數據庫裏不同的組成部分是由不同的組件單獨來(lái)實現(xiàn)的,如分庫分表的管理(lǐ)和(hé)請(qǐng)求分發,由Mycat實現(xiàn),SQL的解析由單機的數據庫實現(xiàn),讀寫分離可能(néng)由網關和(hé)消息隊列來(lái)實現(xiàn),查詢結果的彙總可能(néng)由數據庫接口層來(lái)實現(xiàn)等等,這(zhè)種架構其實是MPP(大(dà)規模并行處理(lǐ))架構的一類實現(xiàn)。
目前開(kāi)源和(hé)商用(yòng)都已經有不少MPP數據庫,開(kāi)源中比較流行的有Greenplum、TiDB、Postgresql XC、HAWQ等,商用(yòng)的如南大(dà)通用(yòng)的GBase、睿帆科技的雪球DB、華爲的LibrA等等,不同的MPP數據庫的側重點也(yě)不一樣,如TiDB更側重于分布式OLTP場景,Greenplum更側重于分布式OLAP場景,這(zhè)些(xiē)MPP數據庫基本都提供了(le)類似Postgresql、Oracle、MySQL那樣的SQL标準支持能(néng)力,能(néng)把一個查詢解析爲分布式的執行計(jì)劃分發到(dào)每台機器上(shàng)并行執行,最終由數據庫本身彙總數據進行返回,也(yě)提供了(le)諸如權限管理(lǐ)、分庫分表、事(shì)務、數據副本等能(néng)力,并且大(dà)多能(néng)夠支持100個節點以上(shàng)的集群,大(dà)大(dà)降低(dī)了(le)數據庫運維的成本,并且使數據庫也(yě)能(néng)夠實現(xiàn)水(shuǐ)平擴展。
數據庫和(hé)Tomcat都能(néng)夠水(shuǐ)平擴展,可支撐的并發大(dà)幅提高(gāo),随着用(yòng)戶數的增長,最終單機的Nginx會(huì)成爲瓶頸
3.8、第七次演進:使用(yòng)LVS或F5來(lái)使多個Nginx負載均衡
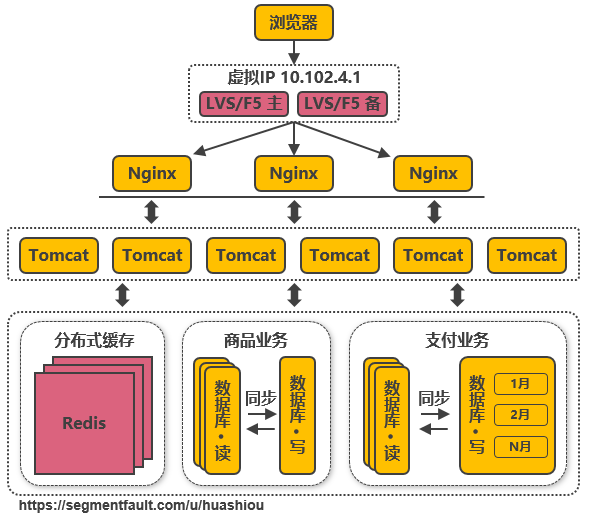
由于瓶頸在Nginx,因此無法通過兩層的Nginx來(lái)實現(xiàn)多個Nginx的負載均衡。圖中的LVS和(hé)F5是工(gōng)作(zuò)在網絡第四層的負載均衡解決方案,其中LVS是軟件,運行在操作(zuò)系統内核态,可對(duì)TCP請(qǐng)求或更高(gāo)層級的網絡協議(yì)進行轉發,因此支持的協議(yì)更豐富,并且性能(néng)也(yě)遠高(gāo)于Nginx,可假設單機的LVS可支持幾十萬個并發的請(qǐng)求轉發;F5是一種負載均衡硬件,與LVS提供的能(néng)力類似,性能(néng)比LVS更高(gāo),但(dàn)價格昂貴。由于LVS是單機版的軟件,若LVS所在服務器宕機則會(huì)導緻整個後端系統都無法訪問,因此需要有備用(yòng)節點。可使用(yòng)keepalived軟件模拟出虛拟IP,然後把虛拟IP綁定到(dào)多台LVS服務器上(shàng),浏覽器訪問虛拟IP時(shí),會(huì)被路由器重定向到(dào)真實的LVS服務器,當主LVS服務器宕機時(shí),keepalived軟件會(huì)自(zì)動更新路由器中的路由表,把虛拟IP重定向到(dào)另外(wài)一台正常的LVS服務器,從(cóng)而達到(dào)LVS服務器高(gāo)可用(yòng)的效果。
此處需要注意的是,上(shàng)圖中從(cóng)Nginx層到(dào)Tomcat層這(zhè)樣畫(huà)并不代表全部Nginx都轉發請(qǐng)求到(dào)全部的Tomcat,在實際使用(yòng)時(shí),可能(néng)會(huì)是幾個Nginx下(xià)面接一部分的Tomcat,這(zhè)些(xiē)Nginx之間通過keepalived實現(xiàn)高(gāo)可用(yòng),其他(tā)的Nginx接另外(wài)的Tomcat,這(zhè)樣可接入的Tomcat數量就能(néng)成倍的增加。
由于LVS也(yě)是單機的,随着并發數增長到(dào)幾十萬時(shí),LVS服務器最終會(huì)達到(dào)瓶頸,此時(shí)用(yòng)戶數達到(dào)千萬甚至上(shàng)億級别,用(yòng)戶分布在不同的地區(qū),與服務器機房距離不同,導緻了(le)訪問的延遲會(huì)明(míng)顯不同
3.9、第八次演進:通過DNS輪詢實現(xiàn)機房間的負載均衡
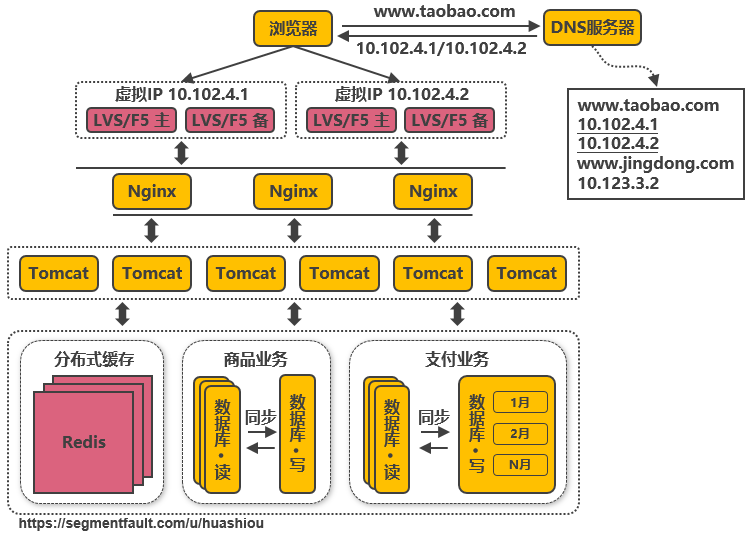
在DNS服務器中可配置一個域名對(duì)應多個IP地址,每個IP地址對(duì)應到(dào)不同的機房裏的虛拟IP。當用(yòng)戶訪問www.taobao.com時(shí),DNS服務器會(huì)使用(yòng)輪詢策略或其他(tā)策略,來(lái)選擇某個IP供用(yòng)戶訪問。此方式能(néng)實現(xiàn)機房間的負載均衡,至此,系統可做到(dào)機房級别的水(shuǐ)平擴展,千萬級到(dào)億級的并發量都可通過增加機房來(lái)解決,系統入口處的請(qǐng)求并發量不再是問題。
随着數據的豐富程度和(hé)業務的發展,檢索、分析等需求越來(lái)越豐富,單單依靠數據庫無法解決如此豐富的需求
3.10、第九次演進:引入NoSQL數據庫和(hé)搜索引擎等技術
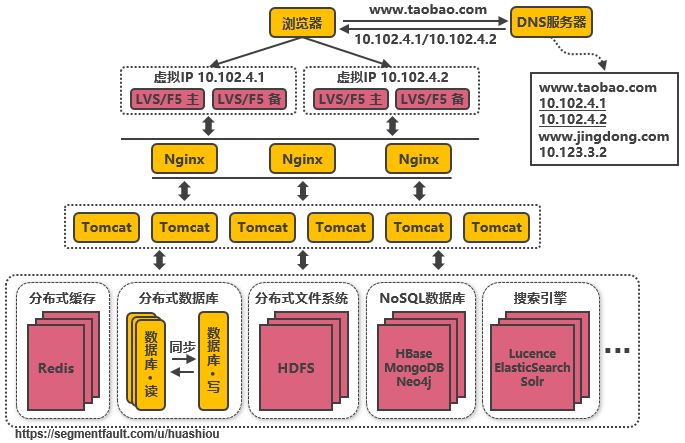
當數據庫中的數據多到(dào)一定規模時(shí),數據庫就不适用(yòng)于複雜(zá)的查詢了(le),往往隻能(néng)滿足普通查詢的場景。對(duì)于統計(jì)報(bào)表場景,在數據量大(dà)時(shí)不一定能(néng)跑出結果,而且在跑複雜(zá)查詢時(shí)會(huì)導緻其他(tā)查詢變慢,對(duì)于全文(wén)檢索、可變數據結構等場景,數據庫天生不适用(yòng)。因此需要針對(duì)特定的場景,引入合适的解決方案。如對(duì)于海量文(wén)件存儲,可通過分布式文(wén)件系統HDFS解決,對(duì)于key value類型的數據,可通過HBase和(hé)Redis等方案解決,對(duì)于全文(wén)檢索場景,可通過搜索引擎如ElasticSearch解決,對(duì)于多維分析場景,可通過Kylin或Druid等方案解決。
當然,引入更多組件同時(shí)會(huì)提高(gāo)系統的複雜(zá)度,不同的組件保存的數據需要同步,需要考慮一緻性的問題,需要有更多的運維手段來(lái)管理(lǐ)這(zhè)些(xiē)組件等。
引入更多組件解決了(le)豐富的需求,業務維度能(néng)夠極大(dà)擴充,随之而來(lái)的是一個應用(yòng)中包含了(le)太多的業務代碼,業務的升級叠代變得困難
3.11、第十次演進:大(dà)應用(yòng)拆分爲小(xiǎo)應用(yòng)
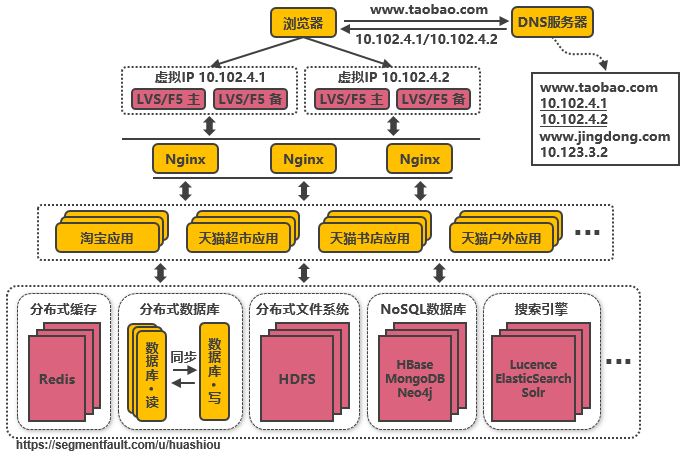
按照業務闆塊來(lái)劃分應用(yòng)代碼,使單個應用(yòng)的職責更清晰,相互之間可以做到(dào)獨立升級叠代。這(zhè)時(shí)候應用(yòng)之間可能(néng)會(huì)涉及到(dào)一些(xiē)公共配置,可以通過分布式配置中心Zookeeper來(lái)解決。
不同應用(yòng)之間存在共用(yòng)的模塊,由應用(yòng)單獨管理(lǐ)會(huì)導緻相同代碼存在多份,導緻公共功能(néng)升級時(shí)全部應用(yòng)代碼都要跟着升級
3.12、第十一次演進:複用(yòng)的功能(néng)抽離成微服務
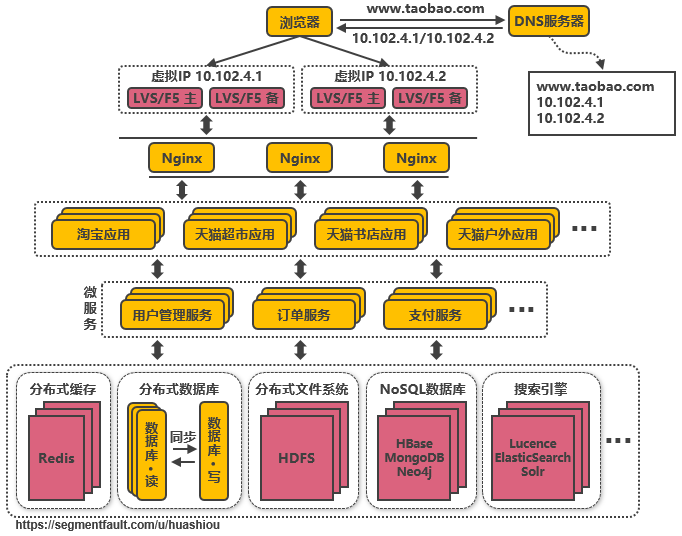
如用(yòng)戶管理(lǐ)、訂單、支付、鑒權等功能(néng)在多個應用(yòng)中都存在,那麽可以把這(zhè)些(xiē)功能(néng)的代碼單獨抽取出來(lái)形成一個單獨的服務來(lái)管理(lǐ),這(zhè)樣的服務就是所謂的微服務,應用(yòng)和(hé)服務之間通過HTTP、TCP或RPC請(qǐng)求等多種方式來(lái)訪問公共服務,每個單獨的服務都可以由單獨的團隊來(lái)管理(lǐ)。此外(wài),可以通過Dubbo、SpringCloud等框架實現(xiàn)服務治理(lǐ)、限流、熔斷、降級等功能(néng),提高(gāo)服務的穩定性和(hé)可用(yòng)性。
不同服務的接口訪問方式不同,應用(yòng)代碼需要适配多種訪問方式才能(néng)使用(yòng)服務,此外(wài),應用(yòng)訪問服務,服務之間也(yě)可能(néng)相互訪問,調用(yòng)鏈将會(huì)變得非常複雜(zá),邏輯變得混亂
3.13、第十二次演進:引入企業服務總線ESB屏蔽服務接口的訪問差異
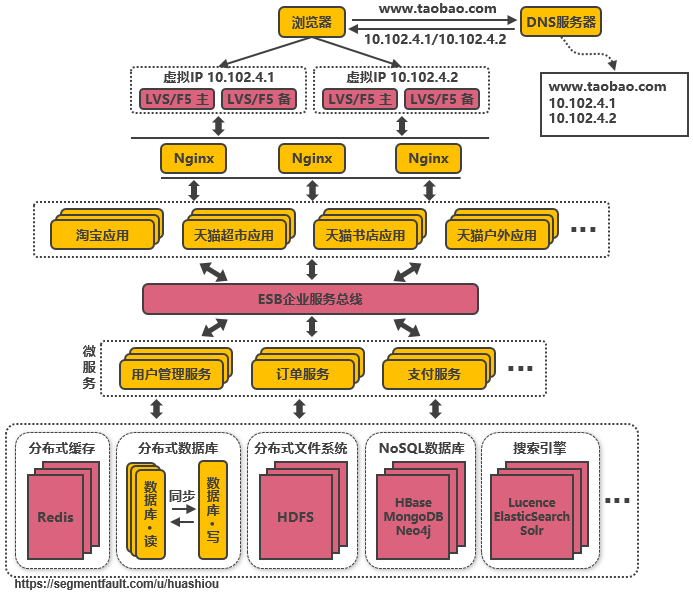
通過ESB統一進行訪問協議(yì)轉換,應用(yòng)統一通過ESB來(lái)訪問後端服務,服務與服務之間也(yě)通過ESB來(lái)相互調用(yòng),以此降低(dī)系統的耦合程度。這(zhè)種單個應用(yòng)拆分爲多個應用(yòng),公共服務單獨抽取出來(lái)來(lái)管理(lǐ),并使用(yòng)企業消息總線來(lái)解除服務之間耦合問題的架構,就是所謂的SOA(面向服務)架構,這(zhè)種架構與微服務架構容易混淆,因爲表現(xiàn)形式十分相似。個人理(lǐ)解,微服務架構更多是指把系統裏的公共服務抽取出來(lái)單獨運維管理(lǐ)的思想,而SOA架構則是指一種拆分服務并使服務接口訪問變得統一的架構思想,SOA架構中包含了(le)微服務的思想。
業務不斷發展,應用(yòng)和(hé)服務都會(huì)不斷變多,應用(yòng)和(hé)服務的部署變得複雜(zá),同一台服務器上(shàng)部署多個服務還要解決運行環境沖突的問題,此外(wài),對(duì)于如大(dà)促這(zhè)類需要動态擴縮容的場景,需要水(shuǐ)平擴展服務的性能(néng),就需要在新增的服務上(shàng)準備運行環境,部署服務等,運維将變得十分困難
3.14、第十三次演進:引入容器化技術實現(xiàn)運行環境隔離與動态服務管理(lǐ)
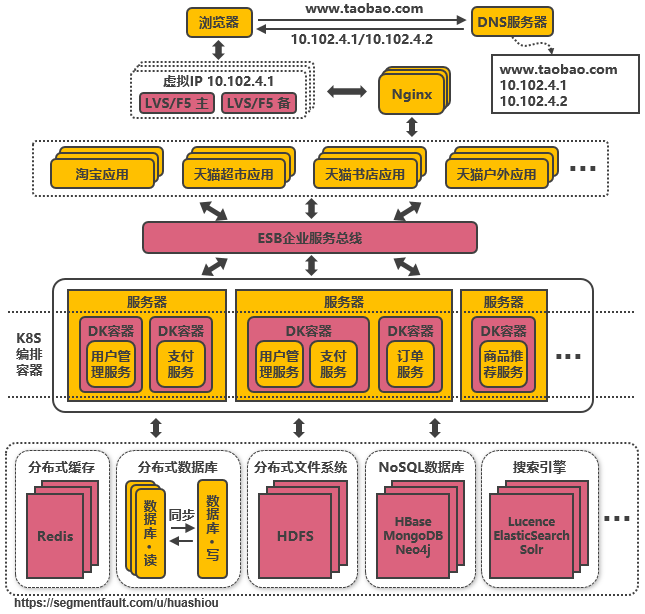
目前最流行的容器化技術是Docker,最流行的容器管理(lǐ)服務是Kubernetes(K8S),應用(yòng)/服務可以打包爲Docker鏡像,通過K8S來(lái)動态分發和(hé)部署鏡像。Docker鏡像可理(lǐ)解爲一個能(néng)運行你(nǐ)的應用(yòng)/服務的最小(xiǎo)的操作(zuò)系統,裏面放(fàng)着應用(yòng)/服務的運行代碼,運行環境根據實際的需要設置好(hǎo)。把整個“操作(zuò)系統”打包爲一個鏡像後,就可以分發到(dào)需要部署相關服務的機器上(shàng),直接啓動Docker鏡像就可以把服務起起來(lái),使服務的部署和(hé)運維變得簡單。
在大(dà)促的之前,可以在現(xiàn)有的機器集群上(shàng)劃分出服務器來(lái)啓動Docker鏡像,增強服務的性能(néng),大(dà)促過後就可以關閉鏡像,對(duì)機器上(shàng)的其他(tā)服務不造成影響(在3.14節之前,服務運行在新增機器上(shàng)需要修改系統配置來(lái)适配服務,這(zhè)會(huì)導緻機器上(shàng)其他(tā)服務需要的運行環境被破壞)。
使用(yòng)容器化技術後服務動态擴縮容問題得以解決,但(dàn)是機器還是需要公司自(zì)身來(lái)管理(lǐ),在非大(dà)促的時(shí)候,還是需要閑置着大(dà)量的機器資源來(lái)應對(duì)大(dà)促,機器自(zì)身成本和(hé)運維成本都極高(gāo),資源利用(yòng)率低(dī)
3.15、第十四次演進:以雲平台承載系統
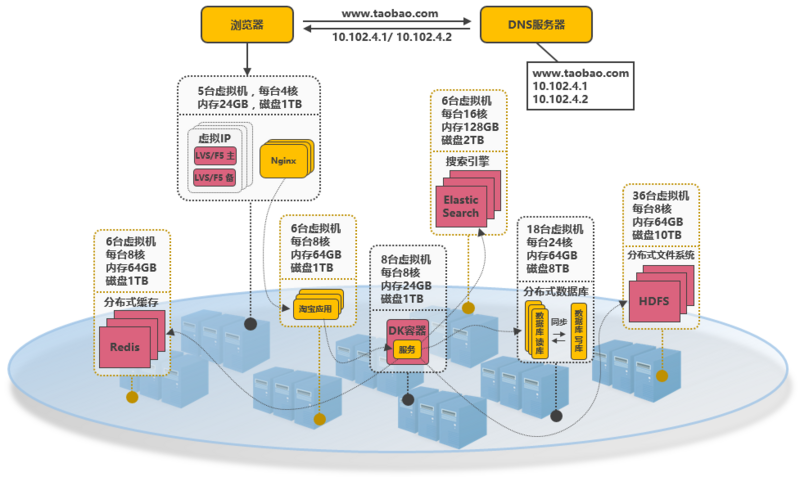
系統可部署到(dào)公有雲上(shàng),利用(yòng)公有雲的海量機器資源,解決動态硬件資源的問題,在大(dà)促的時(shí)間段裏,在雲平台中臨時(shí)申請(qǐng)更多的資源,結合Docker和(hé)K8S來(lái)快(kuài)速部署服務,在大(dà)促結束後釋放(fàng)資源,真正做到(dào)按需付費,資源利用(yòng)率大(dà)大(dà)提高(gāo),同時(shí)大(dà)大(dà)降低(dī)了(le)運維成本。
所謂的雲平台,就是把海量機器資源,通過統一的資源管理(lǐ),抽象爲一個資源整體,在之上(shàng)可按需動态申請(qǐng)硬件資源(如CPU、内存、網絡等),并且之上(shàng)提供通用(yòng)的操作(zuò)系統,提供常用(yòng)的技術組件(如Hadoop技術棧,MPP數據庫等)供用(yòng)戶使用(yòng),甚至提供開(kāi)發好(hǎo)的應用(yòng),用(yòng)戶不需要關系應用(yòng)内部使用(yòng)了(le)什(shén)麽技術,就能(néng)夠解決需求(如音(yīn)視(shì)頻轉碼服務、郵件服務、個人博客等)。在雲平台中會(huì)涉及如下(xià)幾個概念:
IaaS:基礎設施即服務。對(duì)應于上(shàng)面所說的機器資源統一爲資源整體,可動态申請(qǐng)硬件資源的層面;
PaaS:平台即服務。對(duì)應于上(shàng)面所說的提供常用(yòng)的技術組件方便系統的開(kāi)發和(hé)維護;
SaaS:軟件即服務。對(duì)應于上(shàng)面所說的提供開(kāi)發好(hǎo)的應用(yòng)或服務,按功能(néng)或性能(néng)要求付費。
至此,以上(shàng)所提到(dào)的從(cóng)高(gāo)并發訪問問題,到(dào)服務的架構和(hé)系統實施的層面都有了(le)各自(zì)的解決方案,但(dàn)同時(shí)也(yě)應該意識到(dào),在上(shàng)面的介紹中,其實是有意忽略了(le)諸如跨機房數據同步、分布式事(shì)務實現(xiàn)等等的實際問題,這(zhè)些(xiē)問題以後有機會(huì)再拿出來(lái)單獨讨論
4、架構設計(jì)總結
4.1、架構的調整是否必須按照上(shàng)述演變路徑進行?
不是的,以上(shàng)所說的架構演變順序隻是針對(duì)某個側面進行單獨的改進,在實際場景中,可能(néng)同一時(shí)間會(huì)有幾個問題需要解決,或者可能(néng)先達到(dào)瓶頸的是另外(wài)的方面,這(zhè)時(shí)候就應該按照實際問題實際解決。如在政府類的并發量可能(néng)不大(dà),但(dàn)業務可能(néng)很(hěn)豐富的場景,高(gāo)并發就不是重點解決的問題,此時(shí)優先需要的可能(néng)會(huì)是豐富需求的解決方案。
4.2、對(duì)于将要實施的系統,架構應該設計(jì)到(dào)什(shén)麽程度?
對(duì)于單次實施并且性能(néng)指标明(míng)确的系統,架構設計(jì)到(dào)能(néng)夠支持系統的性能(néng)指标要求就足夠了(le),但(dàn)要留有擴展架構的接口以便不備之需。對(duì)于不斷發展的系統,如電商平台,應設計(jì)到(dào)能(néng)滿足下(xià)一階段用(yòng)戶量和(hé)性能(néng)指标要求的程度,并根據業務的增長不斷的叠代升級架構,以支持更高(gāo)的并發和(hé)更豐富的業務。
4.3、服務端架構和(hé)大(dà)數據架構有什(shén)麽區(qū)别?
所謂的“大(dà)數據”其實是海量數據采集清洗轉換、數據存儲、數據分析、數據服務等場景解決方案的一個統稱,在每一個場景都包含了(le)多種可選的技術,如數據采集有Flume、Sqoop、Kettle等,數據存儲有分布式文(wén)件系統HDFS、FastDFS,NoSQL數據庫HBase、MongoDB等,數據分析有Spark技術棧、機器學習算(suàn)法等。總的來(lái)說大(dà)數據架構就是根據業務的需求,整合各種大(dà)數據組件組合而成的架構,一般會(huì)提供分布式存儲、分布式計(jì)算(suàn)、多維分析、數據倉庫、機器學習算(suàn)法等能(néng)力。而服務端架構更多指的是應用(yòng)組織層面的架構,底層能(néng)力往往是由大(dà)數據架構來(lái)提供。
4.4、有沒有一些(xiē)架構設計(jì)的原則?
N+1設計(jì):統中的每個組件都應做到(dào)沒有單點故障;
回滾設計(jì):确保系統可以向前兼容,在系統升級時(shí)應能(néng)有辦法回滾版本;
禁用(yòng)設計(jì)::應該提供控制具體功能(néng)是否可用(yòng)的配置,在系統出現(xiàn)故障時(shí)能(néng)夠快(kuài)速下(xià)線功能(néng);
監控設計(jì):在設計(jì)階段就要考慮監控的手段;
多活數據中心設計(jì):若系統需要極高(gāo)的高(gāo)可用(yòng),應考慮在多地實施數據中心進行多活,至少在一個機房斷電的情況下(xià)系統依然可用(yòng);
采用(yòng)成熟的技術:剛開(kāi)發的或開(kāi)源的技術往往存在很(hěn)多隐藏的bug,出了(le)問題沒有商業支持可能(néng)會(huì)是一個災難;
資源隔離設計(jì):應避免單一業務占用(yòng)全部資源;
架構應能(néng)水(shuǐ)平擴展:系統隻有做到(dào)能(néng)水(shuǐ)平擴展,才能(néng)有效避免瓶頸問題;
非核心則購買:非核心功能(néng)若需要占用(yòng)大(dà)量的研發資源才能(néng)解決,則考慮購買成熟的産品;
使用(yòng)商用(yòng)硬件:商用(yòng)硬件能(néng)有效降低(dī)硬件故障的機率;
快(kuài)速叠代:系統應該快(kuài)速開(kāi)發小(xiǎo)功能(néng)模塊,盡快(kuài)上(shàng)線進行驗證,早日發現(xiàn)問題大(dà)大(dà)降低(dī)系統交付的風(fēng)險;
無狀态設計(jì):服務接口應該做成無狀态的,當前接口的訪問不依賴于接口上(shàng)次訪問的狀态。